Computational experiments with cellular-automata generated images reveal intrinsic limitations of convolutional neural networks on pattern recognition tasks
Abstract
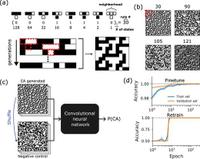
The extraordinary success of convolutional neural networks (CNNs) in various computer vision tasks has revitalized the field of artificial intelligence. The out-sized expectations created by this extraordinary success have, however, been tempered by a recognition of CNNs’ fragility. Importantly, the magnitude of the problem is unclear due to a lack of rigorous benchmark datasets. Here, we propose a solution to the benchmarking problem that reveals the extent of the vulnerabilities of CNNs and of the methods used to provide interpretability to their predictions. We employ cellular automata (CA) to generate images with rigorously controllable characteristics. CA allow for the definition of both extraordinarily simple and highly complex discrete functions and allow for the generation of boundless datasets of images without repeats. In this work, we systematically investigate the fragility and interpretability of the three popular CNN architectures using CA-generated datasets. We find a sharp transition from a learnable phase to an unlearnable phase as the latent space entropy of the discrete CA functions increases. Furthermore, we demonstrate that shortcut learning is an inherent trait of CNNs. Given a dataset with an easy-to-learn and strongly predictive pattern, CNN will consistently learn the shortcut even if the pattern occurs only on a small fraction of the image. Finally, we show that widely used attribution methods aiming to add interpretability to CNN outputs are strongly CNN-architecture specific and vary widely in their ability to identify input regions of high importance to the model. Our results provide significant insight into the limitations of both CNNs and the approaches developed to add interpretability to their predictions and raise concerns about the types of tasks that should be entrusted to them.